Demystifying NLP: Exploring Lexical, Syntactic, and Semantic Processing for Powerful Natural Language Understanding

April 18, 2025

In the post Unlocking the Power of Natural Language Processing: An Introduction and Pipeline Framework for Solving NLP Tasks we have explored high-level techniques and pipeline setup that can be typically used to solve NLP tasks. This post will further extend the idea and we will cover advanced techniques that we can apply to textual data.
The process of text analytics involves three stages as given below:
- Lexical processing: In this stage, we do basic text preprocessing and text cleaning such as tokenization, stemming, lemmatization, correcting spellings, etc. We will be understanding the concepts in the post.
- Syntactic processing: In this step, we extract more meaning from the sentence, by using its syntax this time. Instead of just blindly looking at the words, we here look at the syntactic structures, i.e., the grammar of the language to understand the meaning.
- Semantic processing: Lexical and syntactic processing do not suffice when it comes to building advanced NLP applications such as language translation, chatbots, etc. After performing lexical and syntactic processing, we will still be incapable of understanding the meaning of each word. Here, we try and extract the hidden meaning behind the words which is also the most difficult part for computers.
This post will cover the terminologies and techniques available for all three text analytics stages. The post will also have a link to certain topics that are covered in detail. This post is going to be a lengthy one, therefore I recommend you to bookmark the page and also it can be used as a reference later when you are working on your next NLP project.
Let's dive straight into it and start our discussion with lexical processing.
Lexical Processing
Lexicon describes the vocabulary that makes up a language. Lexical analysis deciphers and segments language into units or lexemes such as paragraphs, sentences, phrases, and words. A few of the techniques involved in Lexical Processing are:
- Word Frequencies and Stop Words
- Stop words removal
- Bag-of-Words and TF-IDF Representation
- Tokenization
- Stemming
- Lemmatization
Let's start understanding each of the techniques in detail.
Word Frequencies and Stop Words
We explore tabular data using info, describe, head, etc methods in Machine Learning tasks. Similarly, word frequencies are an exploration step in NLP tasks. Here we look at word frequency distribution, i.e. visualizing the word frequencies of a given text corpus.
It has been observed that when we have a text corpus and frequency distribution is plotted, it follows Zipf's Law also called Zipf's Distribution.
Zipf's law
Zipf's law states that the frequency of a word is inversely proportional to the rank of the word, where rank 1 is given to the most frequent word, 2 to the second most frequent, and so on. This is also called the power law distribution. Refer to the diagram shown below:
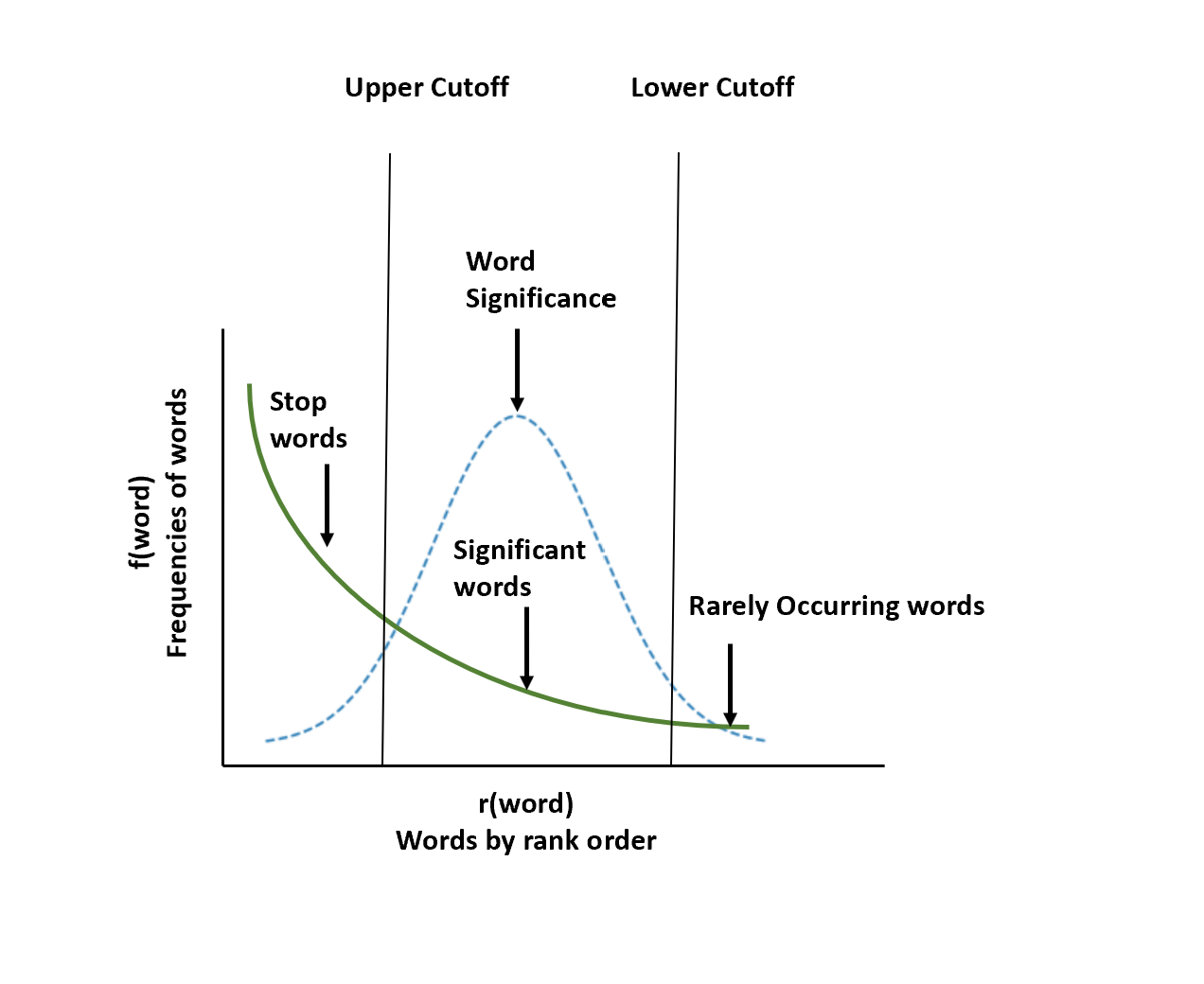
Broadly, there are three kinds of words present in any text corpus as shown in the diagram above:
- Highly frequent words are called stop words, such as ‘is’, ‘an’, ‘the’, etc.
- Significant words, which are very helpful for any analysis and they lie in between the distribution.
- Rarely occurring words are not relevant in describing the document.
Stop words are removed from the text when performing lexical analysis because they provide no useful information in most of the applications and they use a lot of memory because of such high frequency with which they are present
Next, let us look at Python code demonstrating Frequency distribution.
import requests
from nltk import FreqDist
# load the ebook
url = "https://www.gutenberg.org/files/16/16-0.txt"
peter_pan = requests.get(url).text
# break the book into different words using the split() method
peter_pan_words = peter_pan.split()
# build frequency distribution using NLTK's FreqDist() function
word_frequency = FreqDist(peter_pan_words)
# extract the frequency of third most frequent word
freq = word_frequency.most_common(3)[2][1]
# print the third most frequent word - don't change the following code, it is used to evaluate the code
print(freq)In the above code, we are trying to extract the content of the website and thereafter build a frequency distribution using the `nltk` library.
Stop words removal
As discussed above since the most frequently occurring words are the stop words and they don't add value to the corpus so it's a good idea to remove the stop words from the corpus.
NOTE: Exceptional use cases where we want to preserve the grammar of the sentence in the corpus like POS tagging we should not remove stop words.
Refer to the example shown below to remove stop words from the corpus:
import requests
from nltk import FreqDist
from nltk.corpus import stopwords
# load the ebook
url = "https://www.gutenberg.org/files/16/16-0.txt"
peter_pan = requests.get(url).text
# break the book into different words using the split() method
peter_pan_words = peter_pan.split()
# build frequency distribution using NLTK's FreqDist() function
word_frequency = FreqDist(peter_pan_words)
# extract nltk stop word list
stopwords = stopwords.words('english')
# remove 'stopwords' from 'peter_pan_words'
no_stops = [word for word in peter_pan_words if word not in stopwords]
# create word frequency of no_stops
word_frequency = FreqDist(no_stops)As you can see in the example above nltk has a stopword collection list in the English language that we are using to remove the stopwords from the corpus.
Tokenization
Consider a scenario where we are planning to build a classifier for the text messages that will classify text into HAM or SPAM. A question comes to mind, how to extract features from the messages so that they can be used to build a classifier?
When we create any machine learning model such as a spam detector, we will need to feed in features related to each message that the machine learning algorithm can take in and build the model. But this is not the case with text messages. Here we have two columns - one column contains the message and the other contains the label related to the message.
As we know, machine learning works on numeric data, not text. So how do we deal with this problem?
To deal with this problem, we will extract features from the messages. From each message, we extract each word by breaking each message into separate words or 'tokens'. This technique is called tokenization. It is a technique that’s used to split text into smaller elements.
In our spam detector example, we will break each message into different words, it’s called word tokenization. Similarly, we have other types of tokenization techniques such as character tokenization, sentence tokenization, etc. Different types of tokenization are needed in different scenarios.
There are multiple techniques available in Python to achieve tokenization. To tokenize words, we can simply use the split() method that just splits text on white spaces, by default. This method doesn’t always give good results. There are better techniques available using NLTK’s tokenizer which handles various complexities of text. NLTK tokenizer can handle contractions such as “can’t”, “hasn’t”, “wouldn’t”, and other contraction words and split these up although there is no space between them. On the other hand, it is smart enough to not split words such as “o’clock” which is not a contraction word.
In NLTK, we also have different types of tokenizers present that we can use in different applications. The most popular tokenizers are:
- Word tokenizer splits the text into different words.
- Sentence tokenizer splits text into different sentences.
- Tweet tokenizer handles emojis and hashtags that you see in social media texts.
- Regex tokenizer lets us build our custom tokenizer using regex patterns of our choice.
In NLTK, there are various functions like word_tokenize, sent_tokenize, and regexp_tokenize to carry out the task of tokenization.
Bag-of-Words Representation
After having the words with us we need to generate useful features on which we can train the model, as the models need numerical columns to predict the results for our example of text classification.
The central idea is that any given piece of text, i.e., tweets, articles, messages, emails, etc., can be “represented” by a list of all the words that occur in it, where the sequence of occurrence does not matter.
Consider an example of text message classification where our task is to identify whether the email is spam or ham. There are two ways to build a bag of words:
- Frequency approach: We fill the cell with the frequency of a word. (i.e. a cell can have a value of 0 or more)
- Binary approach: We fill the cell with either 0 if the word is not present or 1 if the word is present.
Both of the cases give almost the same results without any major difference. The frequency approach is popular and NLTK also uses the frequency approach instead of the binary approach. Let us look at an example where we are using the frequency-based approach to calculate the bag of words.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
# Removing stop words
vectorizer = CountVectorizer(stop_words='english')
# Sample documents from the text messages dataset
doc1 = 'Nah I don\'t think he goes to usa, he lives around here though'
doc2 = 'Oh Even my brother is not like to speak with me. They seriously treat me like aids patent.'
doc3 = 'Oh k...i\'m watching here though:)'
doc4 = 'Is that seriously how you spell his name?'
# Creating a bag of words representation
X = vectorizer.fit_transform([doc1,doc2,doc3, doc4])
df_bow_sklearn = pd.DataFrame(X.toarray(),columns=vectorizer.get_feature_names())
df_bow_sklearn.head()In the example shown above, we are removing stop words first before counting the frequency of the words. The output from the above sample code is as shown below:

Here, each row represents the individual documents. In our example we have considered four text messages that's why we see four rows in the dataset and columns represent the vocabulary of the four text messages.
Stemming
Stemming is a rule-based technique that just chops off the suffix of a word to get its root form, which is called the ‘stem’. For example, the words ‘driver’ and ‘racing’ will be converted to their root form by just chopping off the suffixes ‘er’ and ‘ing’. So, ‘driver’ will be converted to ‘driv’ and ‘racing’ will be converted to ‘rac’.
As you can see, that driver is not stemmed to drive. We don't have to worry here as all of the variants of the drive will be reduced to 'driv'. Therefore will not impact the analysis. There are two popular stemmers used widely in the industry:
- Porter stemmer: It is also the oldest and most gentle stemmer.
- Snowball stemmer: This is a more versatile stemmer that not only works on English words but also words of other languages such as French, German, Italian, Finnish, Russian, and many more languages.
Python code demonstrating the Porter and Snowball stemmer is given below:
from nltk.tokenize import word_tokenize
from nltk.stem.porter import PorterStemmer
from nltk.stem.snowball import SnowballStemmer
import ast, sys
word = sys.stdin.read()
# instantiate porter stemmer
stemmer_p = PorterStemmer()
stemmer_s = SnowballStemmer('english')
# stem word
stemmed_p = stemmer_p.stem(word)
stemmed_s = stemmer_s.stem(word)
# print stemmed word -- don't change the following code, it is used to evaluate your code
print(stemmed_p)
print(stemmed_s)In the code shown above, the word is read as input from the user and then the stemming is performed on the input word. There are a few other stemmers like Lancaster stemmer which are worth reading about.
Lemmatization
Lemmatization is a more sophisticated or intelligent technique as it doesn’t just chop off the suffix of a word. Instead, it takes an input word and searches for its base word by going recursively through all the variations of dictionary words. The base word, in this case, is called the lemma. Lemmatization only works on correctly spelled words. The most popular lemmatizer is the WordNet lemmatizer.
Python code demonstrating the WordNet lemmatizer is given below:
from nltk.stem import WordNetLemmatizer
import ast, sys
word = sys.stdin.read()
# instantiate wordnet lemmatizer
lemmatizer = WordNetLemmatizer()
# lemmatize word
lemmatized = lemmatizer.lemmatize(word, pos='v')
# print lemmatized word -- don't change the following code, it is used to evaluate your code
print(lemmatized)We know how Stemming and Lematization techniques work. But how to choose in the different scenarios which technique to use?
- A stemmer is a rule-based technique, and hence, it is much faster than the lemmatizer.
- A stemmer typically gives less accurate results than a lemmatizer.
- A lemmatizer is slower because of the dictionary lookup but gives better results than a stemmer.
- For a lemmatizer to perform accurately, we need to provide the part-of-speech tag of the input word (noun, verb, adjective, etc.). Therefore if the accuracy from POS tagging is not good then the accuracy of the lemmatizer will be affected.
NOTE: As an exercise try a bag of word representation for our message classification task after performing Stemming and Lemmatization techniques. Did you see any change in the features of the dataset? Let me know in the comment section.
The stemming and Lemmatization discussed above are part of canonicalization which means to reduce a word to its base form.
TF-IDF Representation
The bag of words representation is very naive as it depends only on the frequency of the words. There is a better representation called TF-IDF representation where TF stands for Term Frequency and IDF stands for Inverse Document Frequency.
$$tf_{t,d} = {\text{frequency of term 't' in document 'd'} \over \text{total terms in document 'd'}}$$
$$idf_{t} = log{\text{total terms in document} \over \text{total document that have the term 't'}}$$
The TF-IDF score for any term in a document is just the product of these two terms:
$$tf-idf = tf_{t,d} * idf_t$$
In TF-IDF importance of words is also considered unlike in the bag of words representation where every word is considered as important. Higher weights are assigned to terms that are present frequently in a document and which are rare among all other documents. On the other hand, a low score is assigned to terms that are common across all documents.
Let us look at the TF-IDF representation of the same text message example that we have seen earlier.
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
import pandas as pd
vectorizer = TfidfVectorizer(stop_words='english')
doc1 = 'Nah I don\'t think he goes to usa, he lives around here though'
doc2 = 'Oh Even my brother is not like to speak with me. They seriously treat me like aids patent.'
doc3 = 'Oh k...i\'m watching here though:)'
doc4 = 'Is that seriously how you spell his name?'
X = vectorizer.fit_transform([doc1,doc2,doc3, doc4])
df_bow_sklearn = pd.DataFrame(X.toarray().round(2),columns=vectorizer.get_feature_names())
df_bow_sklearn.head()Output

After performing all the techniques like Stop word removal, Tokenization, Stemming, Lemmatization, etc, there can be still noise in the data like spelling errors, an issue with tokenization (e.g. Hong Kong is tokenized into two separate words though it represents a single word), etc.
There are a few advanced techniques that can be used to address the above issues. These are:
- Phonetic hashing and the Soundex algorithm: Handle different pronunciations of a word
- The minimum-edit-distance algorithm: A spelling corrector
- Pointwise mutual information (PMI) score: To preserve terms that comprise more than one word
To learn more about the above-stated advanced techniques for performing lexical processing refer to the post: Unleashing the Power of Advanced Lexical Processing: Exploring Phonetic Hashing, Minimum Edit Distance, and PMI Score.
Syntactic Processing
The next step after the lexical analysis is to extract more information from the sentence, by using its syntax this time. Instead of only looking at the words, we look at the syntactic structures, i.e., the grammar of the language to understand what the meaning of given sentence is.
In syntactic analysis, we will aim to understand the roles played by the words in the sentence, and the relationship between words and to parse the grammatical structure of sentences. In other words, it is about analyzing the syntax or the grammatical structure of sentences.
Syntactic processing is widely used in applications such as question-answering systems, information extraction, sentiment analysis, grammar checking, etc. Follwong are some of the popular techniques performed for the syntactic processing of textual data:
- POS tagging techniques
- Constituency and Dependency parsing: Algorithms to parse the grammatical structure of sentences
Let’s start with an example to understand Syntactic Processing and consider two sentences "Canberra is the capital of Australia." and "Is Canberra the of Australia capital."
Both sentences have the same set of words, but only the first one is syntactically correct and comprehensible. Lexical processing techniques wouldn't be able to tell this difference. Therefore, more sophisticated syntactic processing techniques are required to understand the relationship between individual words in the sentence.
The syntactical analysis looks at the following aspects in the sentence that lexical doesn’t:
- Word order and meaning: Changing word order will make it difficult to comprehend the sentence. For example, Dog bites man, man bites dog.
- Role of stop words: Removing stop words can altogether change the meaning of a sentence. For example, Tendulkar lost to Australia, and Tendulkar lost in Australia.
- Morphology of words: Stemming and lemmatization will bring the words to their base form. For example, Our workers are working hard to make our code work. Here if we apply lemmatization we will convert the words workers, working, and work to the lemmatized form. But here morphological words are playing the role of constructing a sentence.
- Parts-of-speech: identifying the correct part-of-speech of a word is important. For example, My uncle is learning driving in a driving school. Here word driving is used two times in the sentence, but the same word has a different meaning.
- Dependencies: How are different words connected? For example, What is the capital of India? In the sentence, the words capital and India are related.
If we consider another sentence, what is the name of the country in whose capital India led the UN delegation on climate change? In this sentence, capital and India are not related to each other.
There are three levels Part-of-speech tagging, Constituency parsing, and Dependency parsing involved in analyzing the syntax of any sentence. Let us start with the part of speech tagging.
Part-of-speech tagging
Part-of-speech tagging or POS tagging is the task of assigning a POS tag to each word depending upon its role in the sentence. Assigning the correct POS tags helps us better understand the intended meaning of a phrase or a sentence and is thus a crucial part of syntactic processing.
Commonly used PoS tags include:
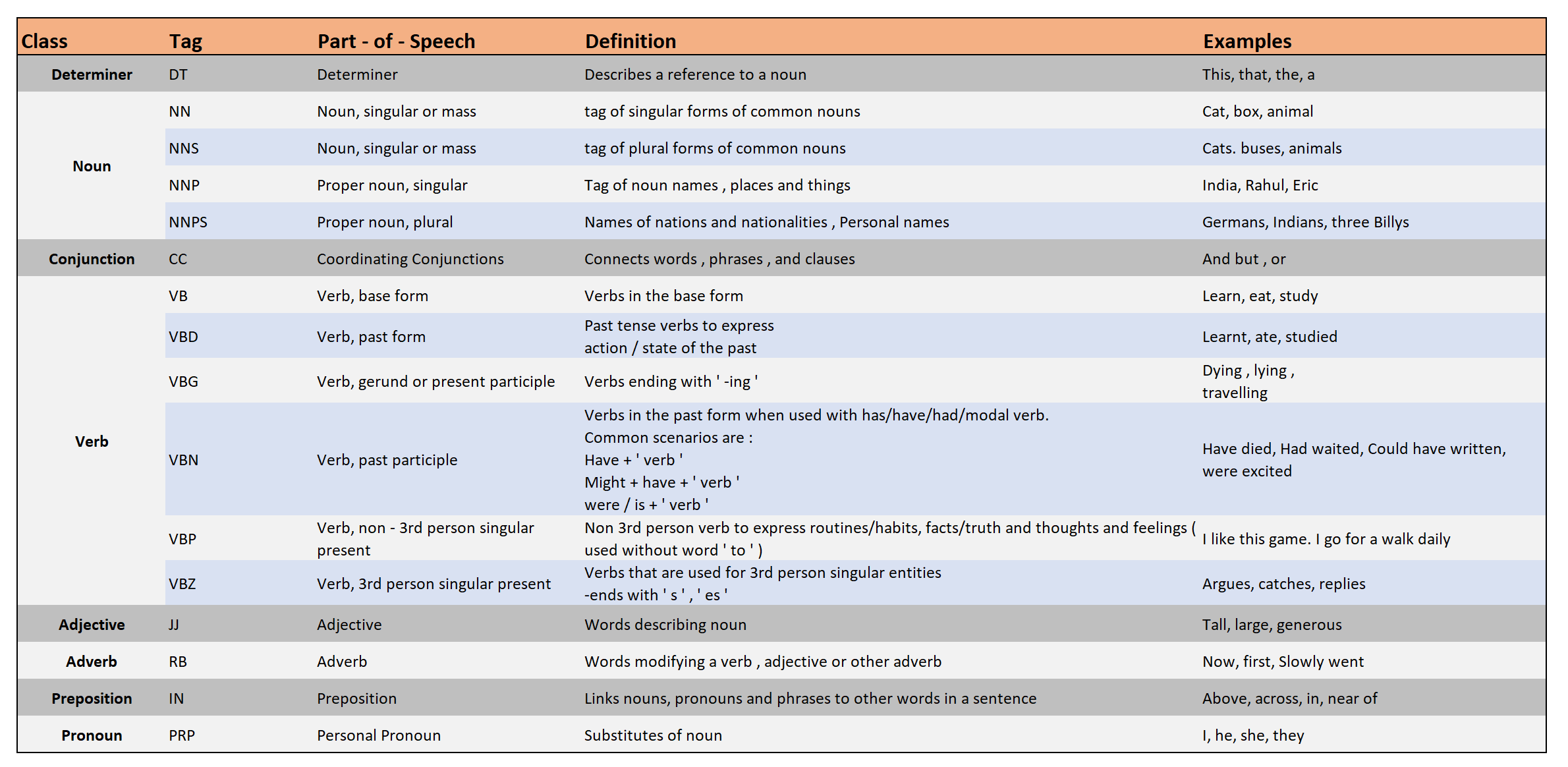
Let's understand the levels with the help of an example sentence: "The little boy went to the park." The POS for the example will be:
The little boy went to the park
Determinant Adjective Noun Verb Preposition Determinant Noun
But why POS tagging is critical and why should you care? Let's consider an example of smart speakers like Google Home where PoS tagging is used in real-time use cases. If we ask Google Home "Where can I get a permit to work in Australia?". Now, the word 'permit' can potentially have two POS tags - a noun and a verb. In the phrase 'I need a work permit', the correct tag of 'permit' is 'noun'. On the other hand, in the phrase "Please permit me to take the exam.", the word 'permit' is a 'verb'.
Therefore for Google Home to correctly get the context of the question that we are asking, POS tagging is crucial. All the subsequent parsing techniques which we are going to see later in the post use the part-of-speech tags to parse the sentence.
There are a lot of POS tags available in the English language which is difficult to remember. There are 36 POS tags in the Penn treebank in NLTK library.
NOTE: The set of POS tags is not standard. Some books/packages may use only the base forms such as NN, VB, JJ, etc without using granular forms. In this post, we will be using POS tagging using the NLTK library.
There are different approaches to POS tagging a sentence:
- Lexicon-based POS Tagging
- Rule-based POS Tagging
- Probabilistic (or stochastic) techniques for POS Tagging
- Deep learning techniques for POS Tagging
To learn more about different techniques that we can use to POS tag the words in the sentence, refer to the post, Demystifying Part-of-Speech (POS) Tagging Techniques for Accurate Language Analysis.
Parsing
Shallow parsing, as the name implies, refers to fairly shallow levels of parsing such as POS tagging, chunking, etc. is a good technique to understand the syntactic of the sentence, but it is not enough to understand the complex grammatical structures and ambiguities in sentences that most human languages comprise. In other words, shallow parsing techniques can help to identify the linguistic role of the word in a sentence but fail to understand how these words are related to each other in a sentence. i.e. It cannot check the grammatical structure of the sentence.
Therefore, we need to learn techniques such as Constituency parsing and Dependency parsing that can help us understand the grammatical structures of complex sentences.
To learn more about different techniques for Constituency parse sentences such as Context-Free grammar (CFG), Top-Down Parsing, Bottom-Up Parsing, and Probabilistic context-free grammar (PCFG) refer to the post Decoding Language Structure: Exploring Constituency Parsing and Dependency Parsing in NLP. The post also helps us understand Dependency parsing and explains how it is different from Constituency parsing.
Application: Information Extraction
Next, let us look at one of the important application of information extraction used widely in industry to solve various business usecases where goal is to extract entities form the given sentences.
Natural language is highly unstructured and complex, making it difficult for any system to process it. Information Extraction (IE) is the task of retrieving structured information from unstructured text data. IE is used in many applications such as conversational chatbots, extracting information from encyclopedias (such as Wikipedia), etc.
A key component in information extraction systems is Named-Entity-Recognition (NER). In general, a named entity refers to the name of people, organization, place, specific date and time, etc. Most named entities correspond to Nouns.
Let’s say we are making a conversational flight-booking system, which can show relevant flights when given a natural-language query such as “Please show me all morning flights from Bangalore to Mumbai next Monday.” For the system to be able to process this query, it has to extract useful named entities from the unstructured text query and convert them to a structured format, such as the following dictionary/JSON object:
{source: 'Bangalore',
destination: 'Mumbai',
day: 'Monday',
time-of-day: 'morning'}Using these entities, we can now easily query a database and get all relevant flight results. So it is trivial to perform NER for such kind of use cases.
To learn a step-by-step process of building a Named-Entity-Recognition (NER) model refer to the post, Mastering Named Entity Recognition: Unveiling Techniques for Accurate Entity Extraction in NLP.
Semantic Processing
Lexical and syntactic processing doesn't suffice when it comes to building advanced NLP applications such as language translation, chatbots, etc. Semantic processing is about understanding the meaning of a given piece of text.
It is probably the most challenging area in the field of NLP, partly because the concept of 'meaning' itself is quite wide, and it is a genuinely hard problem to make machines understand the text the same way as we humans do such as inferring the intent of a statement, meanings of ambiguous words, dealing with synonyms, detecting sarcasm and so on.
Semantic processing is about understanding the meaning of a given piece of text. But what do we mean by 'understanding the meaning' of text? Let's see how the human brain processes meaning.
How does our brain process the meaning of the sentence?
When we hear the sentence "Croatia fought hard before succumbing to France's deadly attack; lost the finals 2 goals to 4", we understand that this text is about football and the FIFA World Cup final, even though the words 'football' and 'FIFA' are not mentioned in the sentence. Also, we understand that the words 'succumb' and 'goal' are used differently than in the sentences "He succumbed to head injuries and died on the spot" and "My life goals".
Our brain can process sentences meaningfully because it can relate the text to other words and concepts it already knows, such as football, FIFA, etc. It can process meaning in the context of the text and can disambiguate between multiple possible senses of words such as 'goal' and 'succumb'.
Also, our brain has an understanding of topics being talked about in a text, such as 'football' and 'FIFA World Cup', even though these exact words are not present in the text.
How machines can process the meaning of a sentence similarly to the human brain?
Semantic text processing focuses on teaching machines to process meaning of the text in similar ways. There are various semantics techniques used such as:
- Word Sense Disambiguation: Identifying the intended meaning of an ambiguous word.
- Distributional Semantics: The technique helps to arrange semantically similar together as compared to other words.
- Topic modeling: Identifying topics being talked about in documents.
We will be covering these semantic techniques, but first, we need to establish a representation of ‘meaning’. Though we often use the term ‘meaning’ quite casually, it is quite non-trivial to answer the question “What is the meaning of meaning, and how do we represent the meaning of a statement?”
We cannot build 'parse trees for meaning' or assign 'meaning tags' to each word. Thus, the first step in semantic processing is to create a model to interpret the 'meaning' of text. To get a sense of why this task is non-trivial, consider a conversation between you and an alien who landed on Earth just a few weeks ago.
Alien (reading a newspaper): What is a country?
You (after some googling): It is a geographical region that is identified as a distinct independent political entity ...
Alien: Can you show me some such regions?
You: Sure, look at Google Maps here - this is India, this is China, here is South Africa…
Alien: And what is independence?
You: Umm if a country has its own independent government and blah blah ….
Alien: Can you show me independence?
You: Not really …
Alien: So independence does not really exist?
You: I wouldn’t really say that …
Therefore it's important to interpret the 'meaning' of text. To learn more about this, refer to the post, Building Block of Semantic Processing: Interpret the meaning of the text.
Word Sense Disambiguation (WSD)
The building block of semantic processing serves as an essential element to understanding the 'meaning' of the word or sentence. And one of the vital task in understanding meaning is to understand how we can solve a common problem of Word Sense Disambiguation (WSD) in semantic analysis.
WSD is the task of identifying the correct sense of an ambiguous word such as 'bank', 'bark', 'pitch' etc. For example, Consider a sentence "The batsman had to duck/bend in order to avoid a duck/bird that was flying too low, because of which, he was out for a duck/zero."
In the above sentence, the word 'duck' is used in three different senses. How do we interpret such words which have multiple meanings? This is what the word sense disambiguation problem is. It is a tagging problem where one needs to identify the sense in which the word is used.
Various supervised and unsupervised techniques are used for word sense disambiguation problems. Let's explore them next.
Supervised Algorithm
Supervised techniques for word sense disambiguation require the input words to be tagged with their senses. The sense is the label assigned to the word by maximizing posterior probability. The common algorithm we use here is the Naive Bayes Classifier. Let's understand how we can build a classifier for the WSD task.
WSD using the Naive Bayes algorithm
The problem of WSD as a supervised problem is formulated as where we are given a training dataset with words assigned different senses from a set of sense labels S and the task is to calculate the posterior probability of sense \(s_k\) for a word w:
$$P(s_k|w) = {P(w|s_k) \over P(w)}P(s_k)$$
To simplify the calculation, we are dropping the denominator (since it is a constant across all the senses) and computing the log probabilities (to prevent underflow), sense assignment is computed as:
$$sense \ of (w) = argmax_{s_k}[logP(w|s_k) + logP(s_k)]$$
Supervised Naive Bayes classifier works on bag-of-words assumptions ignoring co-occurring words in the context of a given word, to resolve the sense. This is one of the algorithms used for the WSD problem but is not a very popular technique. To learn more about how Naive Bayes algorithm works, refer to the post Naïve Bayes Algorithm Detailed Explanation.
Instead of using supervised technique, an unsupervised algorithm like the Lesk algorithm is more widely used in industry. Let's explore this next.
Unsupervised algorithm
Unlike we have seen above in the supervised approach, here words are not tagged with their senses. We cluster the words of similar senses into a single cluster in an unsupervised fashion and attempt to infer the senses. A popular unsupervised algorithm used for word sense disambiguation is the Lesk algorithm.
Lesk Algorithm
As with most machine learning problems, the lack of labeled data is a common problem in building disambiguation models. Thus, we need unsupervised techniques to solve the same problem.
Lesk algorithm uses the wordnet to find the overlapping of the word. WordNet has a network of synonyms called synsets for individual words. Given an ambiguous word and the context in which the word occurs, Lesk returns a Synset with the highest number of overlapping words between the context sentence and different definitions from each Synset.
Synset contains a list of possible different meanings of a word (called, senses) and the definition of each of the senses. Let us explore how we can implement the Lesk algorithm in Python programming language.
import nltk
from nltk.corpus import wordnet
from nltk.corpus import stopwords
#nltk.download('stopwords')
sentence = "The frog is jumping around the bank of the river"
word = 'bank' #the ambiguous word
# Cleaning the sentence
stop_words = set(stopwords.words('english'))
word_tokens = nltk.word_tokenize(sentence) # Tokenize the sentence
#remove stopwords from word_tokens
filtered_sentence = []
for w in word_tokens:
if w not in stop_words: # Remove the stop_words from the sentence
filtered_sentence.append(w)
split_sentence = filtered_sentence
# Choosing that sense of the word 'bank' which maximally overlaps with the given sentence
max_overlap = 0
best_sense = None
for sense in wordnet.synsets(word):
tokenized_sense = set(nltk.word_tokenize(sense.definition()))
common_words = tokenized_sense.intersection(split_sentence)
overlap = len(common_words)
if overlap > max_overlap:
max_overlap = overlap
best_sense = sense
print(best_sense.definition())In the code shown above, we have started performing the basic text processing such as removal of stop words for the given input sentence. After performing preprocessing, we looped over all the sunsets of the given word 'bank' and found the overlap between the definition of the sunsets and the input sentence.
And based, on this overlap the goal is to find the synset definition which has maximum overlap with the input sentence. In this way, the Lesk algorithm will help find the best sense of the given word.
Distributional Semantics
Distributional semantics describes the words which appear in the same contexts have the similar meanings. We use word vectors to represent words in a format that encapsulates their similarity with other words.
The basic idea is to use a technique that can help quantify the similarity between words such that the words that occur in similar contexts are similar to each other. To achieve this task, we need to represent words in a format that encapsulates their similarity with other words. The most commonly used representation of words is using 'word vectors'. There are multiple techniques to represent words as vectors which include occurrence matrix, co-occurrence matrix, word embeddings, etc.
To learn more about such techniques to represent words as vectors and understand the context by analyzing the neighborhood in which the word is used refer to the post, Distributional Semantics | Techniques to represent words as vectors.
Topic Modeling
Topic modeling is the art and science unsupervised technique of identifying the main idea discussed in the text. The algorithm works on the concept of 'Aboutness'. To learn more about various techniques available to build a topic modeling algorithm refer to the post, Diving Deep into Topic Modeling: Understanding and Applying NLP's Powerful Tool.
Bonus: Text Encoding when dealing with non-English language
To deal with the English language we use the ASCII (American Standard Code for Information Interchange) standard. ASCII standard assigned a unique code to each character of the keyboard which was known as ASCII code. For example, the ASCII code of the alphabet ‘A’ is 65, etc.
After the introduction of other languages, the ASCII code was unable to handle different languages as it could handle only 256 bits. Therefore, to deal with non-English data we need text encoding techniques such as Unicode standard (UTF). It supports all the languages in the world - both modern and older ones. One can use UTF-8 or UTF-16 standard. UTF-8 uses only 8 bits to store the character. It was introduced for the backward compatibility of ASCII characters whereas UTF-16 uses 16 bits to store the character.
Summary
This post is a master post that details about most important concepts related to the NLP. The post covers various techniques that can be performed on text data:
Lexical Processing
- Regular expressions
- Tokenization, Stemming, Lemmatization
- TF-IDF model
- Phonetic hashing
- The minimum edit distance algorithm
Syntactic Processing
- POS tagging and HMMs
- CFGs and PCFGs
- Dependency Parsing
- Information Extraction (NER using CRFs and other techniques)
Semantic Processing
- Building Block of Semantic Processing: Terms and Concepts, Entity and Entity Types, Predicates, Arity and Reification, Semantic Associations
- Word Sense Disambiguation (WSD) using the Lesk algorithm
- Distributional Semantics: Occurrence matrix, co-occurrence matrix, and word embeddings
- Topic Modeling
Author Info