Unlocking the Power of Natural Language Processing: An Introduction and Pipeline Framework for Solving NLP Tasks

June 14, 2023

In this post Natural Language Processing we will be understanding what NLP is and various techniques that are used in the process. There are various packages provided to perform NLP or text-related operations in Python such as NLTK, spaCy, TextBlob, Pattern, gensim, MITIE, guess_language, Python wrapper for Stanford CoreNLP, Python wrapper for Berkeley Parser, readability-lxml, BeautifulSoup, etc.
In this post, we will be focusing on NLTK and the spaCy package. Let's get started.
Regular Expressions
Regular Expressions are the sequence of characters that define the search pattern. The below picture represents the expressions that we can use to generate the pattern.
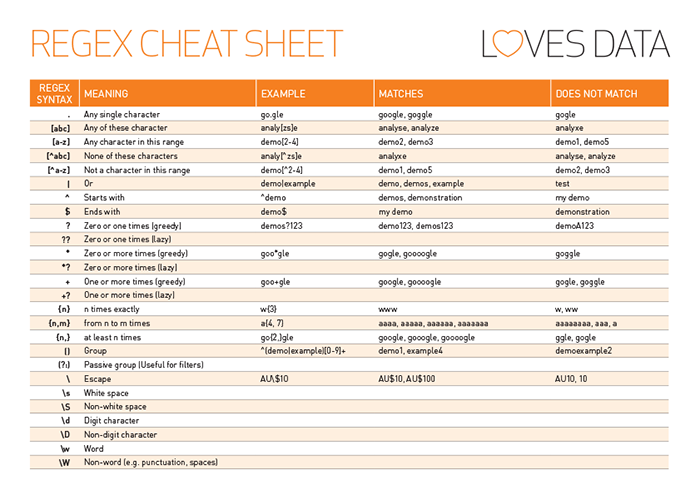
Some of us might be wondering why we need to understand regular expressions in NLP.
In order to process the text, we need to select the right set of text to perform operations. The regular expression comes in handy in this case. Regular expressions are language-independent and can be used with any of the languages.
Here we will be focusing on re package, which is defined for Python. If you are new to regular expressions and want to get started, I would recommend going through Regex 101.
Let's look and some of the methods provided by re package to perform regex searching.
Split and Find all
We use split method to split the string based on the regular expression. And findall the method is used to find all the matching patterns in the string based on the regular expression defined.
Consider an example shown below:
import re
my_string = "Hello All, I am Tavish Aggarwal. Today I will be talking about NLP."
# Regex
sentence_endings = r"[(.?!)]"
print(re.split(sentence_endings, my_string))
# Regex to find capital letters in string
capitalized_words = r"[A-Z]\w+"
print(re.findall(capitalized_words, my_string))
Search and Match
Similar to findall we can use search and match as well as to find the text matching the pattern in the string. The difference between search and match is:
- The search will find something anywhere in the string and return a match object.
- The match will find something at the beginning of the string and return a match object.
Let's look at an example shown below:
# Syntax
# re.search(pattern, string, flags=0)
# re.match(pattern, string, flags=0)
import re
my_string = "hello All, I am Tavish Aggarwal. Today I will be talking about NLP."
capitalized_words = r"[A-Z]\w+"
print(re.search(capitalized_words, my_string))
print(re.match(capitalized_words, my_string))In the example shown above, the search will found All as it is the first string matching the regex defined. But they match will return None since it is not able to find any capital letters at the beginning of the string.
Compile
We can also compile our regular expressions and use them to find the matching text. Consider an example shown below:
h = re.compile('hello')
h.match('hello world')Compile is another syntax where we define our regex using the compile method. And then match our strings.
Sub
This method replaces all occurrences of the regular expression pattern in a string with repl, substituting all occurrences unless max is provided. Consider an example shown below:
# Syntax
# re.sub(pattern, repl, string, max=0)
import re
phone = "2004-959-559 # This is Phone Number"
# Delete Python-style comments
num = re.sub(r'#.*$', "", phone)
print "Phone Num : ", numNow that we have a good understanding of the regular expressions related concepts. It's time to dive into the NLP concepts. Before getting started let's first understand the applications of NLP. And how it is helping industries solve business problems.
Greedy versus Non-greedy Search
When we use a regular expression to match a string, the regex greedily tries to look for the longest pattern possible in the string. For example, when we specify the pattern 'ab{2,5}' to match the string 'abbbbb', it will look for the maximum number of occurrences of 'b' (in this case 5).
This is called a 'greedy approach'. By default, a regular expression is greedy in nature. There is another approach called the non-greedy approach, also called the lazy approach, where the regex stops looking for the pattern once a particular condition is satisfied. Let us explore this with the help of an example.
Suppose, we have the string ‘3000’. Now, if we use the regular expression ‘30+’, it means that we want to look for a string that starts with ‘3’ and then has one or more '0's followed by it. This pattern will match the entire string, i.e. ‘3000’. This is the greedy way. But if we use the non-greedy technique, it will only match ‘30’ because it still satisfies the pattern ‘30+’ but stops as soon as it matches the given pattern.
To use a pattern in a non-greedy way, we can just put a question mark at the end of any of the following quantifiers such as *, +, ?, {m, n}, {m,}, {, n}, and {n}.
Take the string ‘One batsman among many batsmen.’. If we run the patterns ‘bat*’ and ‘bat*?’ on this text, the pattern ‘bat*’ will match the substring ‘bat’ in ‘batsman’ and ‘bat’ in ‘batsmen’ while the pattern ‘bat*?’ will match the substring ‘ba’ in batsman and ‘ba’ in ‘batsmen’.
The pattern ‘bat*’ means look for the term ‘ba’ followed by zero or more ‘t’s so it greedily looks for as many ‘t’s as possible and the search ends at the substring ‘bat’. On the other hand, the pattern ‘bat*?’ will look for as few ‘t’s as possible. Since ‘*’ indicates zero or more, the lazy approach stops the search at ‘ba’.
NLP Applications
There are plenty of companies like Google that have invested a lot in NLP. The applications where NLP is used in industries are described below:
- Cortana and Siri - Various smart assistants use NLP to process text.
- POS (Part of Speech) tagging - Classification of words into adjectives, nouns, adverbs, etc in the sentence
- NER (Name Entity Recognization) - Classification of words in a sentence into people, organizations, states, time, etc
- Sentimental Analytics - Analyze the positivity/negativity of the sentence
Isn't it interesting? There are a number of applications that use NLP to make smart decisions.
Before diving into the NLP pipeline, let's pull the data on which we will be performing operations. Refer to the code shown below:
import requests
from bs4 import BeautifulSoup
import time
import numpy as np
html = requests.get('https://en.wikipedia.org/wiki/Sundar_Pichai')
soup = BeautifulSoup(html.text, 'lxml')
text = [''.join(t.findAll(text = True)) for t in soup.findAll('p')]
text = ''.join(text)Awesome! We are using the Wikipedia page as the article. Now we have the text ready with us.
NLP Pipeline
There are various techniques involved to process the text (including cleaning of data) and perform NLP operations:
- Sentence Segmentation
- Word Tokenization
- Predicting Parts of Speech for Each Token
- Identifying Stop Words
- Text Lemmatization
- Dependency Parsing
- Named Entity Recognition (NER)
- Coreference Resolution
The above steps are followed in a typical NLP pipeline. Though, the execution of steps may vary and can be an individual's choice.
Sentence Segmentation
Sentence Segmentation is the process of breaking up text into sentences. NTLK library provides the sent_tokenize function to convert text into sentences.
Below is an example of demonstrating implementation in Python:
from nltk.tokenize import sent_tokenize
sentences = sent_tokenize(text)
print(sentences)Word Tokenization
Word Tokenization is the process of chopping up a character sequence into pieces called tokens. NTLK library provides the word_tokenize function to convert text into sentences.
from nltk.tokenize import word_tokenize
tokenized_sent = word_tokenize(sentences[3])
unique_tokens = set(word_tokenize(text))
print(unique_tokens)We can also use regexp_tokenize to tokenize sentences based on regular expressions. Consider an example shown below:
from nltk.tokenize import regexp_tokenize
capital_words = r"[A-Z]\w+"
print(regexp_tokenize(text, capital_words))What if we want to see the most common words used in the text once we have text tokenized into words? An interesting requirement isn't it?
We can use the Counter method from the collection package to achieve this. Consider an example shown below:
from collections import Counter
tokens = word_tokenize(text)
lower_tokens = [t.lower() for t in tokens]
bow_simple = Counter(lower_tokens)
print(bow_simple.most_common(20))The output doesn't look promising, because there are stop words in the article. Let's remove them next.
Predicting Parts of Speech for Each Token
After tokenizing sentences into words. The next step is to predict the speech of each token. In this step, we will categorize each word as a noun, adjective, verb, etc.
We use the pos_tag function to add POS (Part Of Speech) to each word as cc (conjunction), RB (adverbs), IN (preposition), NN (noun), and JJ (adjective). Consider an example shown below:
text = nltk.word_tokenize("And now for something completely different")
nltk.pos_tag(text)Identifying Stop Words
The next step in the NLP pipeline is to identify stop words. We may consider removing stop words from the text based on the problem we are trying to solve.
If we are trying to build a search engine, we need to ask ourselves do we need to remove stopwords. (There is a book written named the the).
Consider an example shown below to remove the stopwords from the sentence (If needed):
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
stop_words = stopwords.words('english')
stop_words.extend([')', ',', '.', '[', ']', '(', '``', 'on', 'he', '\'s'])
word_tokens = word_tokenize(text)
filtered_sentence = [w for w in word_tokens if not w in stop_words]
filtered_sentence = []
for w in word_tokens:
if w not in stop_words:
filtered_sentence.append(w)
print(filtered_sentence) Text Lemmatization
In English (and most languages), words appear in different forms. We need to figure out the most basic form or lemma of each word in the sentence so that the same form of words is not treated differently.
Consider an example with a text like: "Yesterday I played carrom. Today I will be playing table tennis."
We can see played and playing is used in a sentence. Those two words are equal and should not be treated differently. So it should be lemmatized as play (to the basic form) in our algorithm.
Python NLTK package provides WordNetLemmatizer function to Lemmatize the sentence. Consider an example shown below:
from nltk.stem import WordNetLemmatizer
tokens = word_tokenize(text)
lower_tokens = [t.lower() for t in tokens]
stop_words = stopwords.words('english')
stop_words.extend([')', ',', '.', '[', ']', '(', '``', 'on', 'he', '\'s'])
alpha_only = [t for t in lower_tokens if t.isalpha()]
no_stops = [t for t in alpha_only if t not in stop_words]
wordnet_lemmatizer = WordNetLemmatizer()
lemmatized = [wordnet_lemmatizer.lemmatize(t) for t in no_stops]
bow = Counter(lemmatized)
print(bow.most_common(10))Dependency Parsing
The next step is to figure out how all the words in our sentences relate. Parsing word dependencies is a remarkably complex task.
NOTE: NLTK package doesn't have dependency parsing model in built. There are other packages which have it and is out of scope of this post.
Named Entity Recognition
NLP task to identify important named entities in the text:
- People, places, organizations
- Dates, states, works of art, and other categories
NLTK package provides ne_chunk_sents function which is used to find Named Entity Recognition (NER) in the data.
sentences = nltk.sent_tokenize(text)
token_sentences = [word_tokenize(sent) for sent in sentences]
pos_sentences = [nltk.pos_tag(sent) for sent in token_sentences]
chunked_sentences = nltk.ne_chunk_sents(pos_sentences, binary=True)
for sent in chunked_sentences:
for chunk in sent:
if hasattr(chunk, "label") and chunk.label() == "NE":
print(chunk)Coreference Resolution
Consider a sentence `Ravi likes to play carrom. He also likes to play table tennis as well.`.
As a human reading this sentence, we can easily figure out that "He" refers to "Ravi". The goal of coreference resolution is to figure out this same mapping by tracking pronouns across sentences. We want to figure out all the words that are referring to the same entity.
NOTE: NLTK package doesn't have coreference resolution model in built. There are other packages which have it and is out of scope of this post.
Reference: NLP Package comparison
We have covered a complete pipeline to perform NLP operations using the NLTK package. Are you ready to code a complete pipeline? I hope it will be a hectic task.
Fortunately, we don't have to code the NLP pipeline to process the text. Thanks to the Spacy library which takes care of it. Let's get familiarized with the spaCy library:
Introduction to spaCy
spaCy is a free, open-source library for advanced Natural Language Processing (NLP) in Python. It's designed specifically for production use and helps us build applications that process and "understand" large volumes of text.
spaCy provides load function which takes care of the complete pipeline involved in NLP which we have seen. Let's see an example:
# Import spacy
import spacy
# Instantiate the English model: nlp
nlp = spacy.load('en',tagger=False, parser=False, matcher=False)
# This runs the entire pipeline.
doc = nlp(article)
# Print all of the found entities and their labels
for ent in doc.ents:
print(ent.label_, ent.text)spaCy can do Dependency Parsing which is not possible with the NLTK package. Consider an example below showing the code to see dependency parsing:
from spacy import displacy
doc = nlp("This is a sentence")
displacy.render(doc, style="dep")NOTE: spaCy models cannot do coreference resolution.
We will be discussing spaCy in detail in our future post.
Summary
Here in this post, we understand:
- re package which is used to perform Regular Expressions on the text.
- The use of NLP in industries and experiencing the typical pipeline of the NLP process.
- How the spaCy package is simplifying the NLP process. We have seen the limitations of NLTK and spaCy packages as well.
Hope you liked this post. Keep Learning!
Author Info