Decoding Language Structure: Exploring Constituency Parsing and Dependency Parsing in NLP

April 18, 2025

Parsing is one of the key tasks which simply means breaking down a given sentence into its 'grammatical constituents'. Parsing is an important step in many applications which helps us better understand the linguistic structure of sentences.
Let’s understand parsing through an example. Let's say we ask a question to Question Answering (QA) system, such as Amazon's Alexa or Apple's Siri, the following question: "Who won the Cricket World Cup in 2015?"
The QA system can respond meaningfully only if it can understand that the phrase 'cricket world cup' is related to the phrase 'in 2015'. The phrase 'in 2015' refers to a specific time frame, and thus modifies the question significantly. Finding such dependencies or relations between the phrases of a sentence can be achieved using parsing techniques.
We will be looking at possible techniques that can help us parse the sentences as shown in the example above. Let's get started.
Constituency Parsers
To deal with the complexity and ambiguity of natural language, we first need to identify and define commonly observed grammatical patterns. This can be done by dividing a sentence into groups of words called constituents based on their grammatical role in the sentence.
Let's take an example sentence, "The fox ate the squirrel." A group of words represents a grammatical unit or a constituent - "The fox" represents a noun phrase, "ate" represents a verb phrase, and "the squirrel" is another noun phrase. Let's take another example sentence: "The quick brown fox jumps over the table". This sentence can be divided into three main constituents. These are: 'The quick brown fox' is a noun phrase, 'jumps' is a verb phrase, and 'over the table' is a prepositional phrase.
Constituency parsers divide the sentence into constituent phrases such as noun phrases, verb phrases, prepositional phrases, adverbial phrases, etc, and check whether the sentence is semantically correct, i.e. whether a sentence is meaningful. Each constituent phrase can itself be divided into further phrases. Refer to the constituency parsed tree shown below.
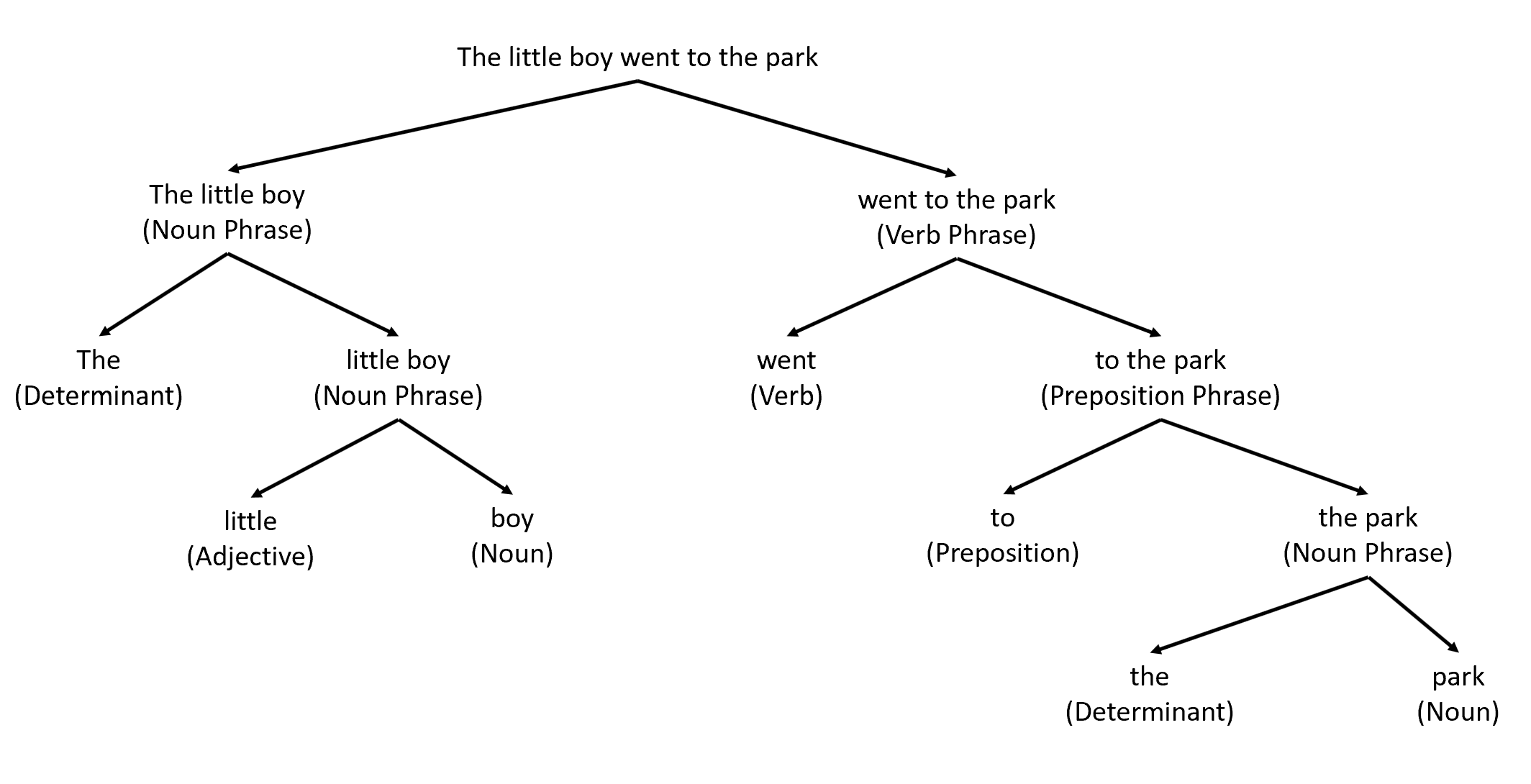
Let's understand the concept of constituencies in a little more detail and explore why in the first place we are attempting to divide the words into constituents. What is the objective?
The rationale for clubbing these words in a single unit is provided by the notion of substitutability which means a constituent can be replaced with another equivalent constituent while keeping the sentence syntactically valid. Let's understand this with the help of an example.
Consider the two sentences "Ram read an article on data science" and "Shruti ate dinner". The groups 'Ram', 'read', 'an article on data science', 'Shruti', 'ate', and 'dinner' of words form a constituent (or a phrase). Replacing the constituency 'an article on data science' (a noun phrase) with 'dinner' (another noun phrase) doesn't affect the syntax of the sentence. Therefore, the sentence "Ram read dinner" is syntactically correct, though the sentence is semantically meaningless.
That is why, constituency parsing is known as paradigmatic parsing as it identifies constituents that are in the same paradigm. The most common constituencies in English are Noun Phrases (NP), Verb Phrases (VP), and Prepositional Phrases (PP).
| Type of Phrases | Definition | Examples |
|---|---|---|
| Noun Phrase | Has a primary noun and other words that modify it | A crazy white cat, the morning flight, a large elephant |
| Verb Phrase | Starts with a verb and other words that syntactically depend on it | saw an elephant, made a cake, killed the squirrel |
| Prepositional Phrase | Starts with a preposition and other words (usually a Noun Phrase) that syntactically depend on it | on the table, into the solar system, down the road, by the river |
There are various other types of phrases, such as an adverbial phrase, a nominal (N), etc., though in most cases we will be working with only the above-mentioned three phrases.
Having an understanding of what constituency parsing is and why it is needed, let's next understand the different types of techniques available to perform constituency parsing for a given sentence.
Context-Free Grammer (CFG)
The most commonly used technique to organize sentences into constituencies is Context-Free Grammar or CFGs. It defines a set of grammar rules that specify how words can be grouped to form constituents such as noun phrases, verb phrases, etc. For example NP -> DT N | NP PP.
The production rule says that a noun phrase can be formed using either a determiner (DT) followed by a noun (N) or a noun phrase (NP) followed by a prepositional phrase (PP). Let's attempt to apply the above-mentioned CFG rule to the sentence "The/DT man/N". The man is a noun phrase that follows the first rule i.e., NP -> DT N.
In general, any production rule can be written as A -> B C, where A is a non-terminal symbol (NP, VP, N, etc.) and B and C are either non-terminals or terminal symbols (i.e., words in vocabulary such as the flight, man, etc.). A few examples in the form CFG rules can be written include S -> NP VP, NP -> DT N| N| N PP, DT -> 'the'| 'a', V -> 'ate', etc.
Grammar can be applied irrespective of the context in which A appears. There are two approaches for parsing sentences using CFGs:
- Top-down: We start from the starting symbol S and produce each word in the sentence.
- Bottom-up: We start from the individual words and reduce them to the sentence S.
Let's understand them in detail.
Top-Down Parsing
Top-down parsing starts with the start symbol S at the top and uses the production rules to parse each word one by one. We continue to parse until all the words have been allocated to some production rule.
The example shown below shows all the paths the parser tried for parsing the sentence "The man saw dogs". We are given the grammar production rules and our goal is to check if we can correctly parse the sentence with the given grammar rules or not.
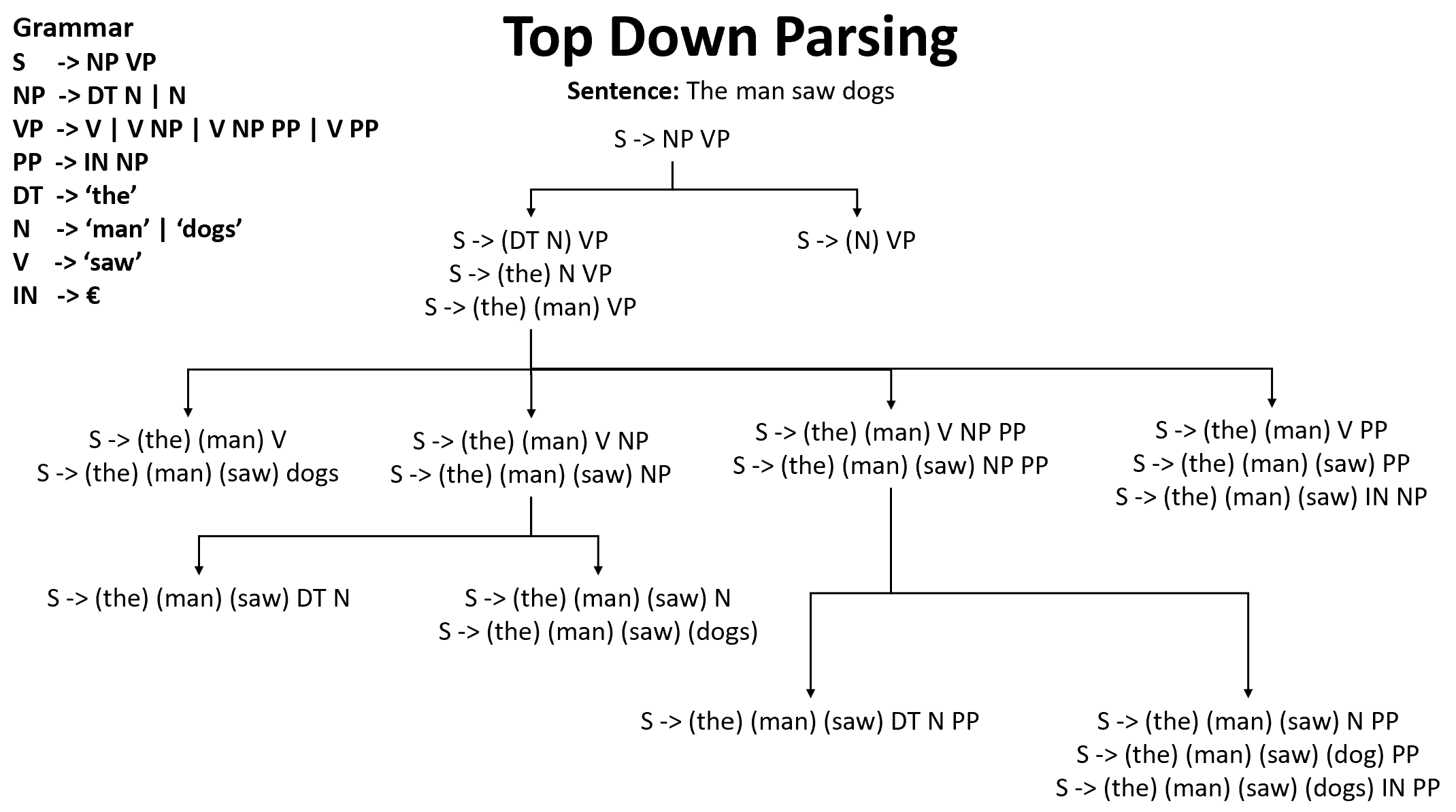
In the process, it is common that we often encounter dead ends, i.e. points where no production rule can be applied to produce a right-hand side from the left-hand side. In such cases, the algorithm needs to backtrack and try some other rule.
Let us look at the Python code and see how we can perform the Top-Down parsing.
import nltk
from nltk.parse import RecursiveDescentParser
grammar = nltk.CFG.fromstring("""
S -> NP VP
NP -> Det N | Det N PP
VP -> V | V NP | V NP PP
PP -> P NP
Det -> 'a' | 'an' | 'the'
N -> 'man' | 'park' | 'dog' | 'telescope'
V -> 'saw' | 'walked'
P -> 'in' | 'with'
""")
str = "the man saw a dog in the park with a telescope"
#Using a top-down parser
rdstr = RecursiveDescentParser(grammar)
#Print each of the trees
for tree in rdstr.parse(str.split()):
print(tree)
nltk.app.rdparser()The recursive descent parser is a commonly used type of top-down parser. The above Python code implemented is using the same.
The problem of Left Recursion
There is an issue with top-down parsing when the left-hand side of the term is present in the right-hand side of the rule. Consider an example sentence "The man saw a car" and grammar rules as given below:
- S -> NP VP
- NP -> DT N
- VP -> VP NP| V
- DT -> the
- N -> man
The rule VP -> VP NP runs into an infinite loop and no parse tree will be obtained. This is the problem of left recursion. This problem can be resolved using the bottom-up approach. Let's understand the bottom-up parser next.
Bottom-up Parsing
The Bottom-up approach reduces each terminal word to a production rule, i.e. reduces the right-hand-side of the grammar to the left-hand-side. It continues the reduction process until the entire sentence has been reduced to the start symbol S.
Let's consider the example sentence "The angry bear chased the squirrel" and grammar:
- S -> NP VP
- NP -> Det Nom | PropN
- Nom -> Adj Nom| N
- VP -> V NP | V Adj|V NP PP
- PP -> P NP
- Det -> 'the' | 'a'
- N -> 'bear' | 'squirrel'
- Adj -> 'angry'| 'little'
- V -> 'chased'
The below diagram demonstrates how to bottom-up parse the above-given sentence for the given grammar.
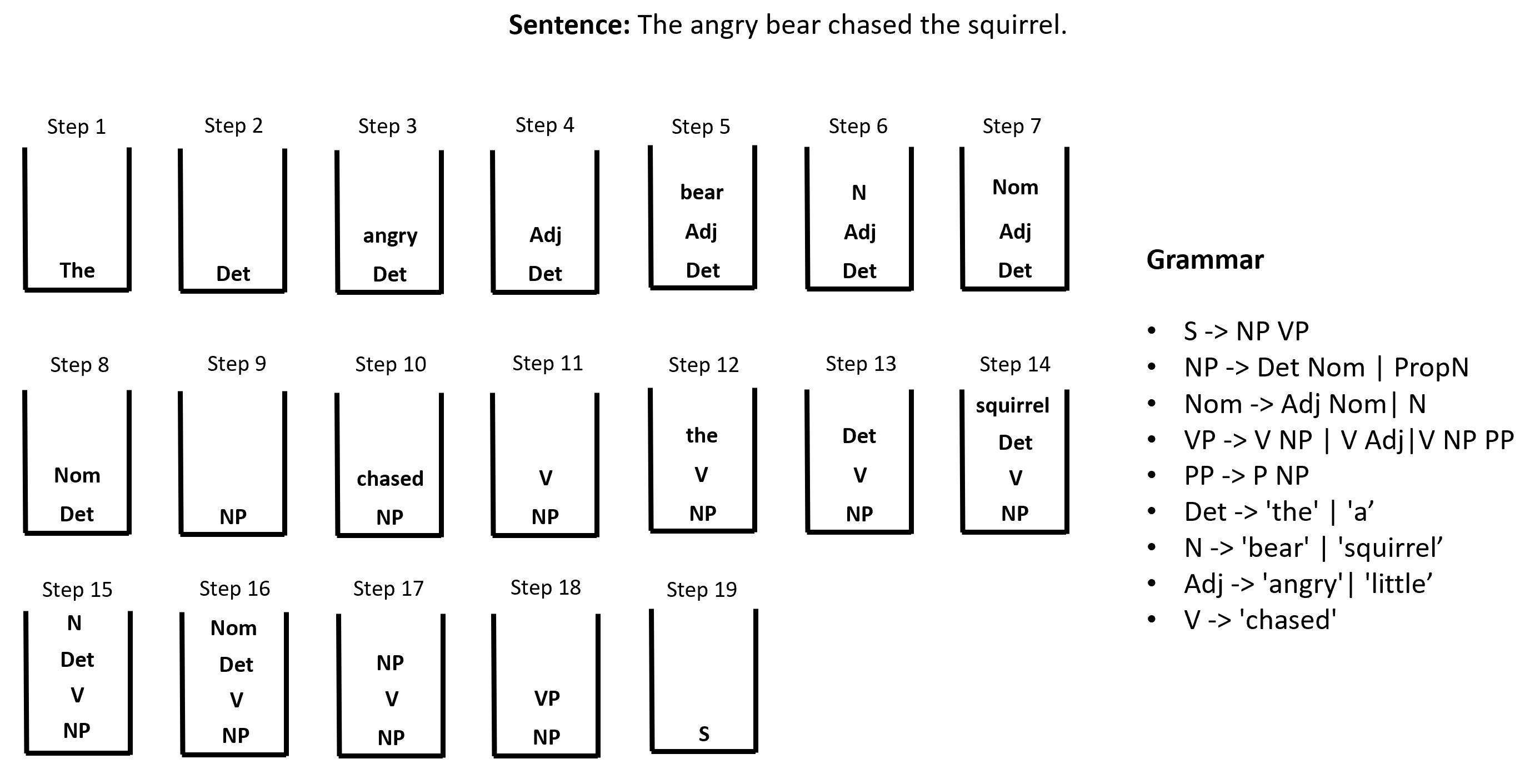
To solve the problem, we start with an empty stack and at every step we perform one of two operations i.e., shifting or reducing. We start with the first word and then we keep on parsing the sentence with the grammar production rules as shown in the example above by either performing one of two available operations as shown in the diagram above. The goal is to reach the S state and no word needs to be parsed in a given sentence.
The example shows that we are successfully able to parse the sentence with the stated grammar rules. This means our sentence is grammatically valid.
Let us look at Python code demonstrating how to perform bottom-up parsing programmatically.
import nltk
from nltk.parse import ShiftReduceParser
grammar = nltk.CFG.fromstring("""
S -> NP VP
PP -> P NP
VP -> V
NP -> DT N | N | NP PP
P -> 'over'
V -> 'jumped'
N -> 'bear'| 'table'
DT -> 'the'
""")
str = "the bear jumped over the table"
srp = ShiftReduceParser(grammar)
for t in srp.parse(str.split()):
print(t)There are many types of bottom-up parsers. But in the code shown above, the shift-reduce parser is used as it is one of the most commonly used bottom-up parsing algorithms. The shift-reduce parser parses the words of the sentence one-by-one either by shifting a word to the stack or reducing the stack by using the production rules.
Ambiguities in Parse Trees
There can be multiple valid parsers for the same sentence hence adding the ambiguity. Let us consider an example sentence "The man caught fish with a net." and grammar rules as shown below:
- S -> NP VP
- PP -> P NP
- VP -> V NP| VP PP | V
- NP -> DT N | N | NP PP
- P -> ‘with’
- V -> ‘caught’
- NP -> ‘man’| ‘fish’ | ‘net’
- DT -> ‘the’ | ‘a’
There are two possible parse trees. I will leave it up to you to run the example and convince yourself that there are two parse trees possible. Both of the obtained parse trees change the meaning of the sentence. If we look at the sentence carefully, it has two meanings "The man caught a fish using a net" and "The man caught a fish. And the fish was having some net"
In one parse, the prepositional phrase "with a net" is associated with "The man" whereas in another parse it is associated with "fish". Now, from common sense, we know that the phrase "with a net" is associated with "The man", i.e. it is the man who has the net, not the fish. But how do we make the algorithm use this common sense?
In such cases we want our algorithms to figure out the most likely parse tree. As always, the way to make algorithms understand the concept of likelihood is to use probabilistic techniques. Let's explore probabilistic context-free grammars or PCFGs algorithm.
Probabilistic context-free grammars (PCFGs)
Probabilistic context-free grammars (PCFGs) come in handy when we encounter an ambiguous sentence and grammar which could lead to multiple parse trees. In general, since natural languages are inherently ambiguous (at least for computers to understand), there are often cases where multiple parse trees are possible. In such cases, we need a way to make the algorithms figure out the most likely parse tree.
Both top-down and bottom-up techniques that we have gone through so far will generate multiple parse trees. None of these trees is grammatically incorrect, but some of these are improbable to occur in normal conversations. To identify which of these trees is the most probable, we use the notion of probability.
Probabilistic Context-Free Grammars (PCFGs) are used when we want to find the most probable parsed structure of the sentence. PCFGs are grammar rules, similar to what we have seen, along with probabilities associated with each production rule. For example:
NP -> Det N (0.5) | N (0.3) |N PP (0.2)
It means that the probability of an NP breaking down to a ‘Det N’ is 0.50, to an 'N' is 0.30, and to an ‘N PP’ is 0.20. Note that the sum of probabilities of a given production rule is 1.00.
Let us consider a Python code shown below demonstrating how to code PCFGs.
import nltk
from nltk.parse import pchart
pcfg_grammar = nltk.PCFG.fromstring("""
S -> NP VP [1.0]
PP -> P NP [1.0]
VP -> V NP [0.3]| VP PP [0.4] | V [0.3]
NP -> DT N [0.4] | N [0.2] | NP PP [0.25] | N V [0.15]
P -> 'until' [0.4] | 'with' [0.6]
V -> 'chased' [0.4] | 'stumbled' [0.2] | 'fell' [0.4]
N -> 'lion' [0.5]| 'deer' [0.4] | 'it' [0.1]
DT -> 'the' [1.0]
""")
str = "the lion chased the deer until it fell"
parser = pchart.InsideChartParser(pcfg_grammar)
#print all possible trees, showing probability of each parse
for t in parser.parse(str.split()):
print(t)One point to understand here is that the probabilities are learned from a pre-tagged corpus where a large number of sentences have been parsed manually. One can use Penn Treebank and compute the probabilities by counting the frequencies of production rules. This is similar to how we computed the transition and emission probabilities in HMMs (Hidden Markov Model).
To learn more about HMMs refer to the post, Demystifying Part-of-Speech (POS) Tagging Techniques for Accurate Language Analysis.
Bonus: Chomsky Normal Form
Until now both top-down and bottom-up parsing approaches, we have defined multiple CFG rules. We have defined CFGs which are of the form A -> B where both A and B are non-terminals (e.g. Nom -> Noun), and some are of the form A -> B where A is a non-terminal while B is a terminal (Det -> the).
It is often useful to use a standardized version of production rules by converting grammar to what is called the Chomsky Normal Form (CNF). It states that any CFG rule can be written in the form given below:
- A -> B C
- A -> a
- S -> ε
where A, B, and C are non-terminals (POS tags), a is a terminal (term), S is the start symbol of the grammar and ε is the null string. In CNF form, the production rule should be always in one of the three forms shown above. For example, the grammar rule VP -> V is not the CNF form grammar rule.
Let us look at an example of how to convert CFG to CNF rules. Let's take an example production rule in CFG form VP -> V NP PP which can be written in CNF form as VP -> V (NP1) and NP1 -> NP PP. Let's take one more example rule in CFG form VP -> V which can be written in CNF form as VP -> V (VP1) and VP1 -> ε.
Dependency Parsers
Dependency parsing is a recent topic in the field of NLP whose study involves a fairly deep understanding of the English grammar and parsing algorithms. This is a highly advanced topic, and this post covers the basics of dependency parsing techniques.
Constituency parsing discussed so far is a parsing technique where groups of words or constituencies comprise the basic structure of a parse tree. But in dependency grammar, constituencies (such as NP, VP, etc.) do not form the basic elements of grammar, but rather dependencies are established between the words themselves.
For example, consider the dependency parse tree of the sentence "man saw dogs" which is created using the tool displaCy dependency visualiser. The dependencies can be read as follows: 'man' is the subject of the sentence (the one who is doing something); 'saw' is the main verb (something that is being done); while 'dogs' is the object of 'saw' (to whom something is being done).
In a dependency parse, we start from the root of the sentence, which is often a verb. In the example above, the root is the word 'saw'. The intuition for the root is that it is the main word that describes the 'aboutness' of a sentence. Although the sentence is also about 'man', and 'dogs', it is most strongly about the fact someone 'saw' someone.
The dependencies from the root to the other words are: nsubj (man) is the nominal subject of the verb 'saw' and direct object of the verb (dobj) is 'dogs'
Notice that here in dependency parsing, unlike constituency parsing, there is no notion of phrases or constituencies, but rather relationships are established between the words themselves.
The basic idea of dependency parsing is based on the fact that each sentence is about something, and usually contains a subject (the doer), a verb (what is being done), and an object (to whom something is being done).
In general, Subject-Verb-Object (SVO) is the basic word order in present-day English. Of course, many sentences are far more complex to fall into this simplified SVO structure and there are sophisticated dependency parsing techniques to handle such complex cases.
Fixed Word Order and Free Word Order
Modern languages can be divided into two broad types. These are fixed-word order and free-word order. Let's understand what this means.
Fixed Word Order is one where SVO occurs in a fixed order in the sentence i.e., English language. For example, 'Dog bites man' and 'Man bites dog'. Changing the order of words changes the meaning of the sentence. Whereas, Free Word Order is one where SVO does not occur in a fixed order in the sentence i.e., Hindi, Spanish Language, etc. Consider the following Hindi sentences:
विश्व कप में भारत ने श्रीलंका को हराया
Subject Object Verb
श्रीलंका को विश्व कप में भारत ने हराया
Object Subject Verb
The two sentences in Hindi have the same meaning though they are written in two different word orders (SOV, OSV).
CFGs cannot handle free word order languages (It will require a lot of production rules which will be computationally challenging). Free word order languages such as Hindi are difficult to parse using constituency parsing techniques. This is because, in such free-word-order languages, the order of words/constituents may change significantly while keeping the meaning the same. It is thus difficult to fit the sentences into the finite set of production rules that CFGs offer.
So to parse such free word order languages we use dependency parsing. Dependencies in a sentence are defined using the elements Subject-Verb-Object (SVO). The following table shows examples of three types of sentences: declarative, interrogative, and imperative, and it shows how the dependencies of the sentences are defined.
| Declarative | Shyam complimented Suraj Subject Verb Object |
|---|---|
| Interrogative | Will the teacher take the class today? Aux Subject Object (Aux: auxiliary verbs such as will, be, can) |
| Imperative | Stop the car! Verb Object (No subject in such sentences) |
Universal Dependencies
Dependency grammar (which is also called word grammar) is based on identifying role dependencies between the words in the sentence and not about defining the production grammar rules. Such grammar is best suited for the free word-other languages where dependencies are represented as labeled arcs of the form h -> d (l) where h is the "head" of dependency, d is the "dependent", and l is the "label" assigned to arc.
Now the question arises, how do we find the dependencies and assign the labels to the dependencies for words in the sentence?
There is a project called universaldependencies.org developed by Standford which is a universal framework for dependency annotations and has a list of dependency labels that can be assigned to words. The most commonly used dependency labels from the universal dependency project are listed below:
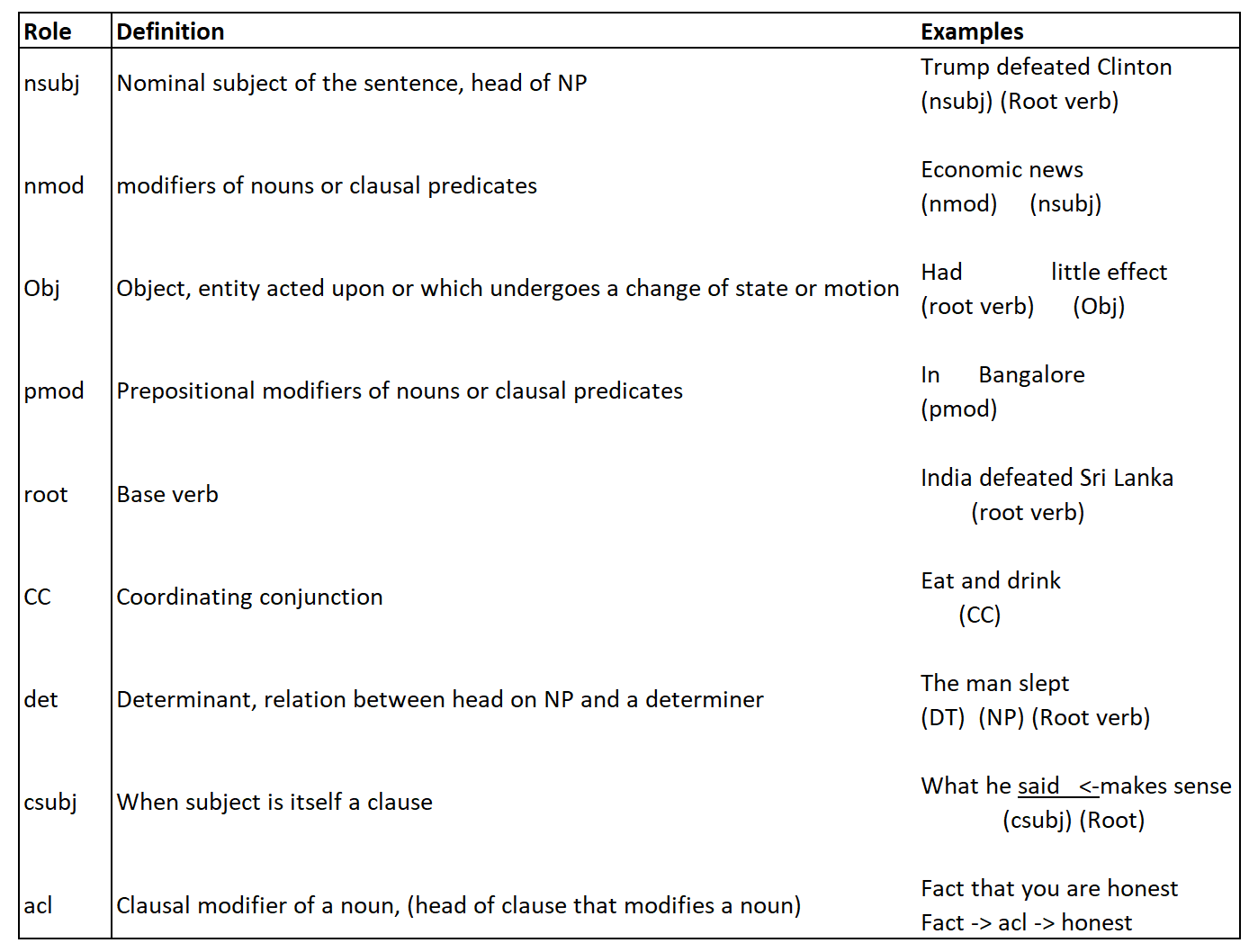
NLTK doesn't have support for dependency grammar as of now. But there are different types of dependency grammar freely available on the internet and one such popular dependency grammar is Standford Parser. The package returns POS tags, the most probable constituency parse, and the dependency parse.
Algorithms for Dependency Parsing
After knowing the details of the dependency parsing technique, one question is still unanswered. How do we create a dependency parse for the given sentence?
One of the major advancements to detect the dependencies is the "Universal Dependencies" project. These dependencies represent the syntactical dependencies between the head of the dependency and the dependent i.e., h -> d (l). But there is no grammatical set of rules like we have observed earlier during constituency parsing techniques to find such dependencies. However, there are a lot of methods to detect the dependencies in a given language.
Projectivity
A variety of approaches has been explored for this (ML, graphical models) by which we can identify different parts of the sentences. One breakthrough in finding such dependencies is called the idea of projectivity of a dependency parse. Let us take an example sentence, "United canceled the morning flights to Houston". In this sentence word 'canceled' is the root of the sentence and the word 'flight' is the object of the word 'canceled'.
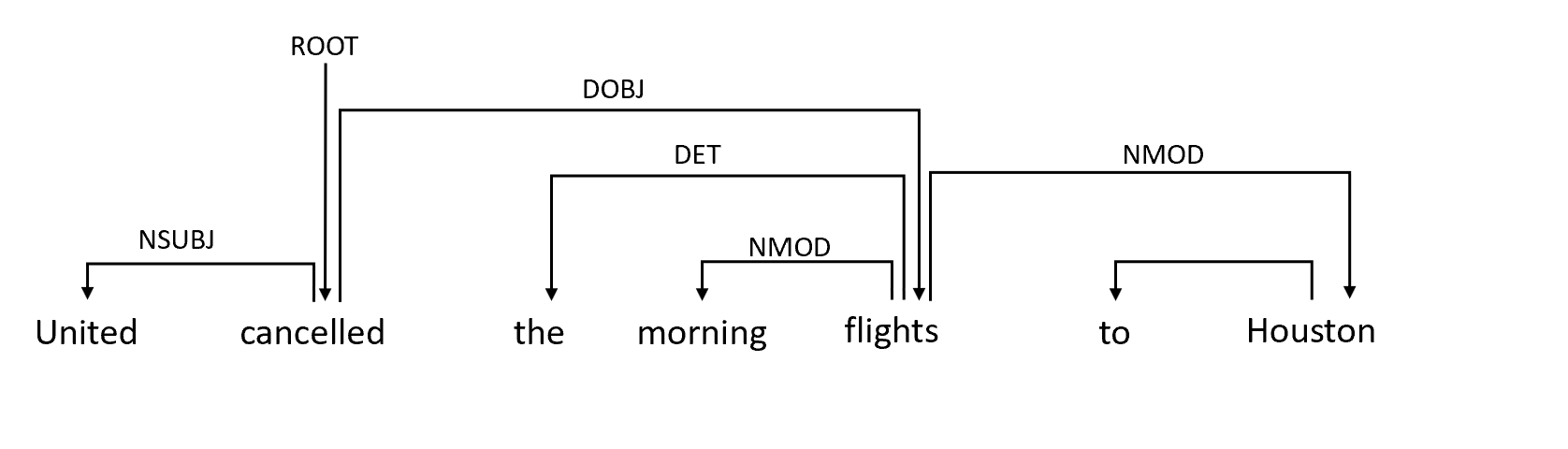
Between the root of the sentence and object, there are other words as well like 'the' and 'morning'. If there is a path from the root of the sentence to all the dependents then the sentence graph is called a projective graph. In such cases, arrows representing the dependencies will not intersect each other and such sentences can be solved using the constituency parsing technique that we have looked at earlier. And we can easily represent dependency parse in the form of CFGs.
However, some sentences are not projective and cannot be converted to CFGs. Let us see an example sentence "JetBlue canceled our flight this morning which was already late" which is syntactically valid but is not projective as the dependency arrows are intersecting each other.

If we observe that 'canceled' is the root of the sentence and 'morning' is modified by the root 'canceled' but there is no dependency path between the word 'canceled' and 'morning' which can lead us to the word 'morning' from the word 'canceled'.
Therefore, to summarize we can build CFGs for the projective sentences but non-projective sentences are still a challenge at hand.
Shift-Reduce Parser
Dependency parsing is performed based on some kind of machine learning technique as there are no defined rules like CFGs to parse the dependencies. We have treebanks for constituency parsing, in the same way, there are a lot of treebanks created to perform dependency parsing. Penn Treebank is a good example of dependency parsing.
Actually dependency parsing technique is much more complex, therefore in this post, we will have an intuitive understanding of how to build a dependency parse tree for the given sentence and details will be skipped. A dependency tree can be built up from the variant of a bottom-up parsing technique called a shift-reduce parser. Let's understand how it works.
In the shift-reduce parser, there is an oracle, stack, and sequence of words for the given input sentence. Oracle reads the words from the input sentence, performs operations on the stack and thereby returns the output which is the dependency element for the words.
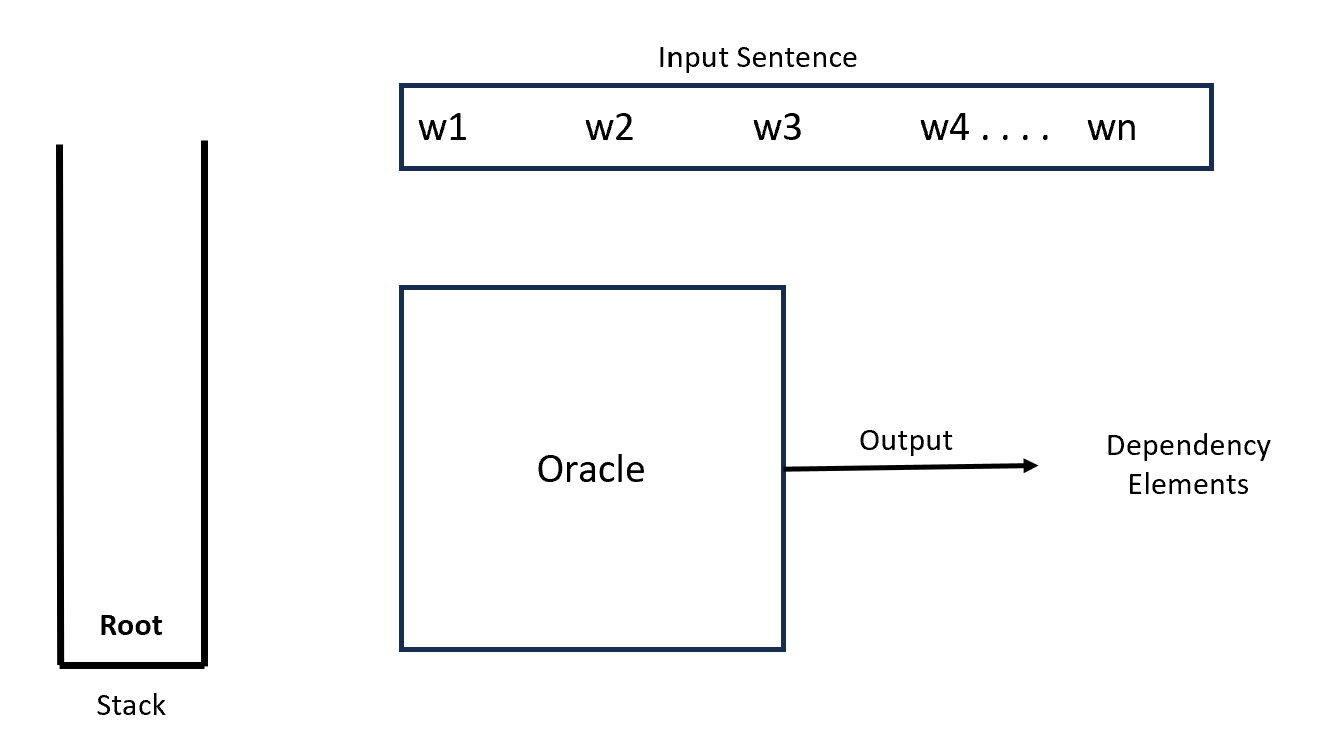
Initially, we push the 'root' element to the stack, and thereafter, Oracle at every step does one of three things, which are:
- Shift operation: It may shift the input words from the given sentence onto the stack.
- Reduce operation: In constituency parsing, we tend to reduce the symbols on the stack to non-terminal symbols. But here we look at the top two symbols on the stack and we perform two classes of operations.
These are:- Left reduction: This rule says that there is a link that can be established between the bottom element of the stack to the top element of the stack. For example, Root -> w1 where the second element is head and the top element is dependent.
- Right reduction: It is the opposite of left reduction where we establish a link or dependency from the top element to the second element of the stack. For example, w1 -> Root.
After performing reduction, we throw away the top element (or dependent and retain the head element on the stack) from the stack and we keep on performing the same operation until we reach only the root element left over on the stack and the input words are also empty.
But how we will know when we should be performing reduce or shift operations? Like in constituency parsing, we have rules that guide us in forming some kind of state machine; here in dependency parsing, we do not have a state machine but an oracle that will be learning from the examples that are passed to it.
To train this oracle we use a supervised learning technique where we take a dataset from Treebank which comprises dependency grammar that has been built by experts on several sentences. We then run a hypothetical shift to reduce parsing with the ground truth we already know and Oracle learns.
Dependency parsing is a fairly advanced topic whose study involves a much deeper understanding of English grammar and parsing algorithms. Therefore, designing this supervised technique to train the oracle is out of the scope of this post.
Summary
In this post, we have understood how constituency and dependency parsing works. Let us consider an example sentence and parse the sentence using constituency and dependency parsing techniques to summarize the difference between the two techniques.
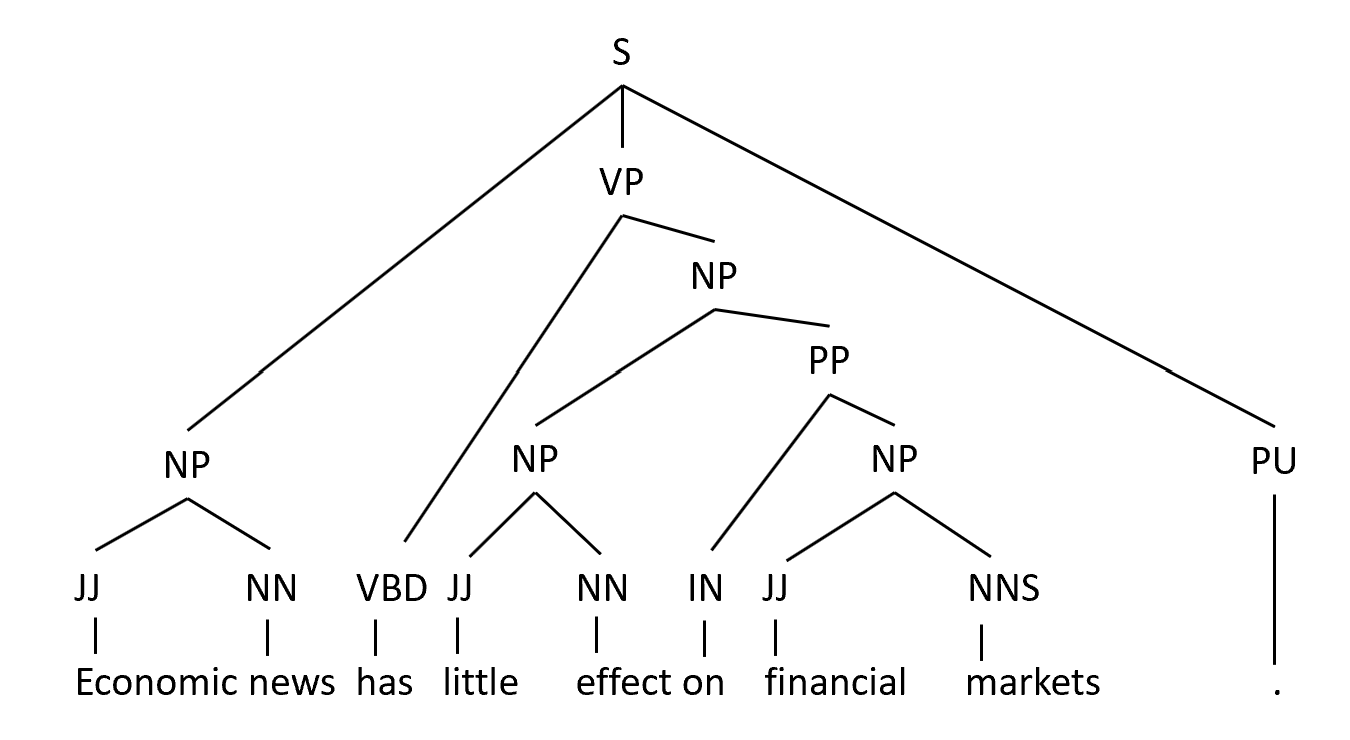
As shown above, in the constuency parsing technique we first assign POS tags to the words and then parse the sentence using the production rules across tags. Such a kind of grammar is called constituency grammar. And below diagram shows the dependency parser for the same sentence.
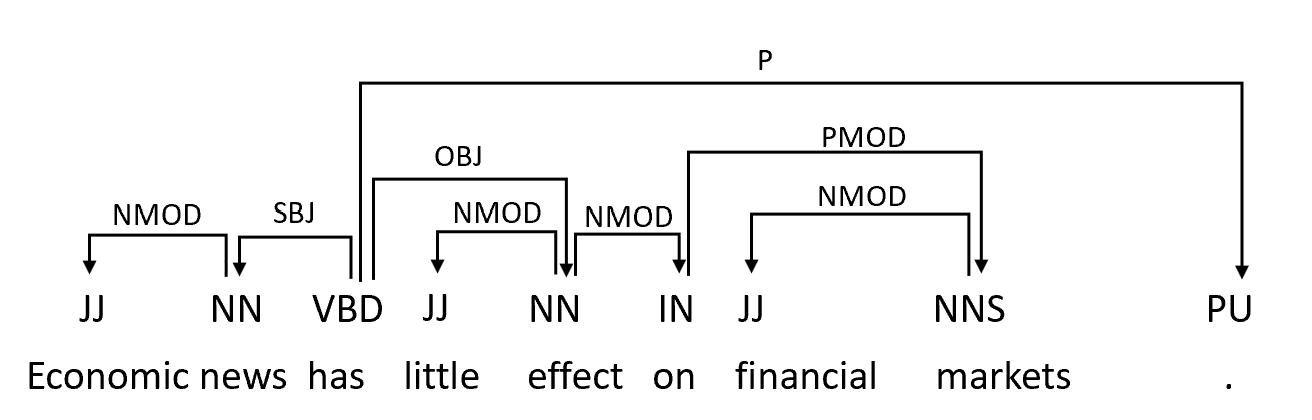
To summarise, Constituency Parsers divide the sentence into constituent phrases such as noun phrases, verb phrases, prepositional phrases, etc. Each constituent phrase can itself be divided into further phrases. The constituency parse tree given below divides the sentence into two main phrases - a noun phrase and a verb phrase. The verb phrase is further divided into a verb, a prepositional phrase, and so on.
Whereas, Dependency Parsers do not divide a sentence into constituent phrases but rather establish relationships directly between the words themselves. The figure below is an example of a dependency parse tree of the sentence.
Author Info